Transfer style using CycleGANs
- 6 minsSee the GitHub repository here.
Central problem
For the Advanced Machine Learning class at IT University of Copenhagen, other two students and I aimed to learn and analyze the main strengths and challenges of using CycleGANs to generate a Monet-styled painting based on an input photography.
Domain
The model belongs to the unpaired image-to-image translation domain. As explained in the original CycleGAN paper, the “primary focus is learning the mapping between two image collections, rather than between two specific images, by trying to capture correspondences between higher-level appearance structures. Therefore, our method can be applied to other tasks, such as painting → photo, object transfiguration, etc. where single sample transfer methods do not perform well” (https://arxiv.org/abs/1703.10593).
The identification of higher-level appearance structures makes it great to train CycleGANs to learn the features of Monet paintings and apply them to real images.

Unpaired images.
Data characteristics
The dataset of choice contains four directories: monet_tfrec, photo_tfrec, monet_jpg, and photo_jpg. The monet_tfrec and monet_jpg directories contain the same painting images, and the photo_tfrec and photo_jpg directories contain the same photos.
The monet directories contain Monet paintings. We used these images to train our model.
The photo directories contain photos. We will add Monet-style to these images. Other photos outside of this dataset can be transformed but did not experiment on that based on time constrains.
Files:
- monet_jpg - 300 Monet paintings sized 256x256 in JPEG format
- monet_tfrec - 300 Monet paintings sized 256x256 in TFRecord format
- photo_jpg - 7028 photos sized 256x256 in JPEG format
- photo_tfrec - 7028 photos sized 256x256 in TFRecord format
Link to the dataset: https://www.kaggle.com/competitions/gan-getting-started/data
Central method and CycleGAN architecture
Architecture
Our method of choice is CycleGAN for image-to-image translation with unpaired training data. The model aims to learn characteristics from images (in this case, Monet paintings) and translate them to other images.
We implemented the CycleGAN architecture following the Pix2Pix (paired image-to-image translation) architecture. Unlike Pix2Pix models, Cycle GANs use two generators and two discriminators to achieve results. Generators and discriminators use instance normalization and these are their tasks:
- Generator: It transforms input images into Monet’s artistic style and viceversa.
- Discriminator: Differentiates between real Monet images and generated images.
Architecture Summary
- GAN 1: Translates real images (collection 1) to Monet (collection 2).
- GAN 2: Translates Monet (collection 2) to real images (collection 1).
We can summarize the generator and discriminator models from GAN 1 as follows:
- Generator Model 1:
- Input: Takes real images (collection 1).
- Output: Generates Monet (collection 2).
- Discriminator Model 1:
- Input: Takes Monet from collection 2 and output from Generator Model 1 (fake Monet).
- Output: Likelihood of image is from collection 2.
- Losses:
- Cycle consistency loss
Similarly, we can summarize the generator and discriminator models from GAN 2 as follows:
- Generator Model 2:
- Input: Takes Monet (collection 2).
- Output: Generates real images (collection 1).
- Discriminator Model 2:
- Input: Takes real images from collection 1 and output from Generator Model 2 (fake real images).
- Output: Likelihood of image is from collection 1.
- Losses:
- Cycle consistency loss
So far with this architecture, the models are sufficient for generating plausible images in the target domain but are not translations of the input image. This is when the CycleGAN model differs from the Pix2Pix model: Pix2Pix uses a combination of adversarial loss and L1 loss between the generated and target images, while CycleGAN incorporates cycle-consistency loss in addition to adversarial loss.
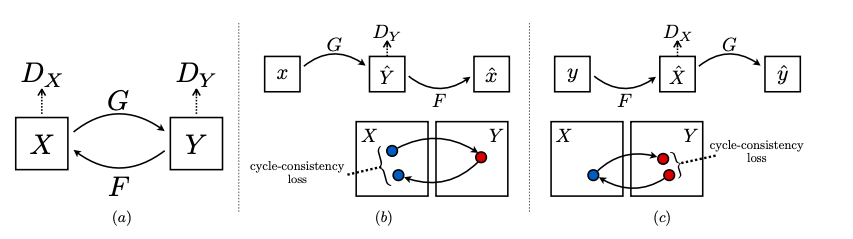
CycleGAN architecture.
Losses
-
Adversarial loss: to improve the performance of both generator and discriminator. Generator aims to minimize this loss against its corresponding Discriminator that tries to maximize it. But adversarial losses alone cannot guarantee that the learned function can map an individual input xi to a desired output yi. To solve this problem, the authors used the cycle consistency loss.
-
Cycle consistency loss: The CycleGAN encourages cycle consistency by adding an additional loss to measure the difference between the generated output of the second generator and the original image, and the reverse. This acts as a regularization of the generator models, guiding the image generation process in the new domain toward image translation.. it calculates the L1 loss between the original image and the final generated image, which should look same as original image. It is calculated in two directions:
- Forward Cycle Consistency: Domain-B -> Generator-A -> Domain-A -> Generator-B -> Domain-B
- Backward Cycle Consistency: Domain-A -> Generator-B -> Domain-B -> Generator-A -> Domain-A
The cycle consistency loss also helps solving the mode collapse problem, in which all input images map to the same output image and the optimization fails to make progress. This type of loss helps reducing the space of possible mapping functions, so the model learns to differenciate style instead of other features.
- Identity loss: It encourages the generator to preserve the color composition between input and output. This is done by providing the generator an image of its target domain as an input and calculating the L1 loss between input and the generated images.
- Domain-A -> Generator-A -> Domain-A
- Domain-B -> Generator-B -> Domain-B
Training and hyperparameters
We split the original data into training (80%) and test (20%):
Shape of X_train_A: (5630, 256, 256, 3)
Shape of X_test_A: (1408, 256, 256, 3)
Shape of X_train_B: (240, 256, 256, 3)
Shape of X_test_B: (60, 256, 256, 3)
We initially trained the model for 10 epochs, with a batch size of 1, learning rates of 2e-4 and Adam optimizers for both the discriminators and generators. CycleGANs are known for being very heavy and time consuming to train, so we used the U-Cloud cluster as well as the available 30 hours of Kaggle GPU for our training process.
Evaluation
Style is very difficult to define and hence to measure. Measuring how well style is captured by the model was a challenging tasks, and despite being plenty of quantitative solutions out there, most of them are inaccurate or just less reliable than the human eye. For this particular task and due to time constrains, we decided to evaluate the results visually, analyzing if the Monet style was present in the output images.
We also plot the training losses to help understand if the model is improving or not, and to decide if it is needed to increase the initial learning rate.
Best Results

Example after one epoch.

Example after 50 epochs.